.avif)
Tabby with Replicas and a Reverse Proxy

Tabby operates as a single process, typically utilizing resources from a single GPU.This setup is usually sufficient for a team of ~50 engineers. However, if you wish to scale this for a larger team, you'll need to harness compute resources from multiple GPUs. One approach to achieve this is by creating additional replicas of the Tabby service and employing a reverse proxy to distribute traffic among these replicas.
This guide assumes that you have a Linux machine with Docker, CUDA drivers, and the nvidia-container-toolkit already installed.
Let's dive in!
Creating the Caddyfile
Before configuring our services, we need to create a Caddyfile that will define how Caddy should handle incoming requests and reverse proxy them to Tabby:
http://*:8080 {
handle_path /* {
reverse_proxy worker-0:8080 worker-1:8080
}
}
Note that we are assuming we have two GPUs in the machine; therefore, we should redirect traffic to two worker nodes.
Preparing the Model File
Now, execute the following Docker command to pre-download the model file:
docker run --entrypoint /opt/tabby/bin/tabby-cpu \
-v $HOME/.tabby:/data tabbyml/tabby \
download --model StarCoder-1B
Since we are only downloading the model file, we override the entrypoint to tabby-cpu to avoid the need for a GPU
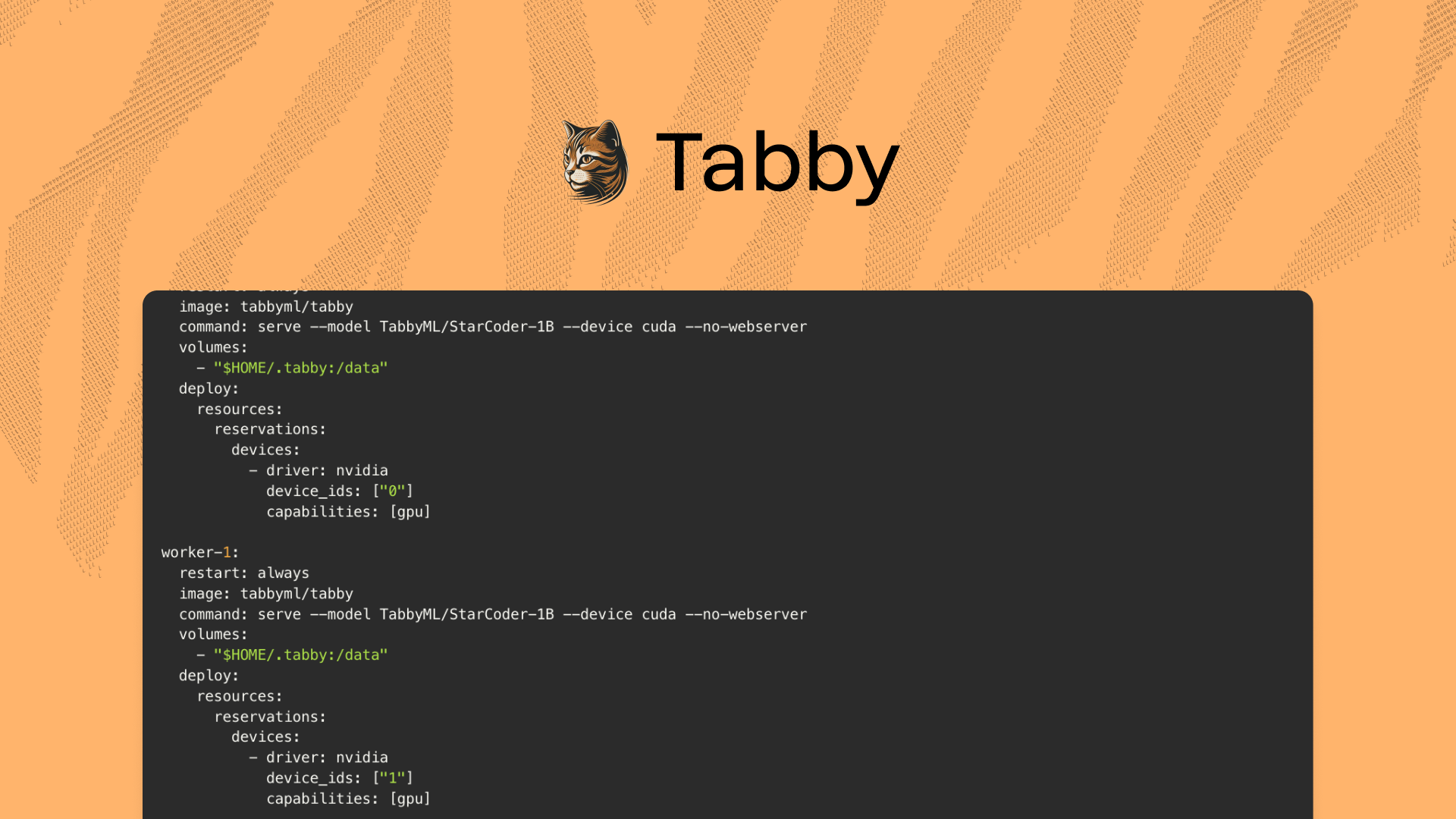
Creating the Docker Compose File
Next, create a docker-compose.yml file to orchestrate the Tabby and Caddy services. Here is the configuration for both services:
version: '3.5'
services:
worker-0:
restart: always
image: tabbyml/tabby
command: serve --model TabbyML/StarCoder-1B --device cuda --no-webserver
volumes:
- "$HOME/.tabby:/data"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0"]
capabilities: [gpu]
worker-1:
restart: always
image: tabbyml/tabby
command: serve --model TabbyML/StarCoder-1B --device cuda --no-webserver
volumes:
- "$HOME/.tabby:/data"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["1"]
capabilities: [gpu]
web:
image: caddy
volumes:
- "./Caddyfile:/etc/caddy/Caddyfile:ro"
ports:
- "8080:8080"
Note that we have two worker nodes, and we are using the same model for both of them, with each assigned to a different GPU (0 and 1, respectively). If you have more GPUs, you can add more worker nodes and assign them to the available GPUs (remember to update the Caddyfile accordingly!).
Starting the Services
With the docker-compose.yml and Caddyfile configured, start the services using Docker Compose:
docker-compose up -dVerifying the Setup
To ensure that Tabby is running correctly behind Caddy, execute a curl command against the health endpoint:
curl -L 'http://localhost:8080/v1/completions' \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"language": "python",
"segments": {
"prefix": "def fib(n):\n ",
"suffix": "\n return fib(n - 1) + fib(n - 2)"
}
}'
The response should indicate that Tabby is healthy and ready to assist you with your coding tasks.
Securing Your Setup (Optional)
For those interested in securing their setup, consider using Caddy directives like forward_auth and integrating with a service like Authelia. For more details on this, refer to the Caddy documentation on forward_auth.
And there you have it! You've successfully set up Tabby with Caddy as a reverse proxy. Happy coding with your new AI assistant!
As an additional note, since the release of v0.9.0, Tabby enterprise edition now includes the built-in account management system. For more information, refer to the official documentation for details.
Stay Updated with Tabby News
Subscribe to our newsletter for the latest updates and news about Tabby.


.png)
.png)
Discover Tabby Unlock Your Coding Potential
Get Started with our Community Plan Today
Simple self-onboarding
Free community plan
Local-first deployment
Explore Full Features with Team or Enterprise Plans
Enterprise-first experience
Flexible deployment options
Enhanced security support