.avif)
Running Tabby Locally with AMD ROCm

.png)
info
Tabby's ROCm support is currently only in our nightly builds. It will become stable in version 0.9.
For those using (compatible) AMD graphics cards, you can now run Tabby locally with GPU acceleration using AMD's ROCm toolkit! 🎉
ROCm is AMD's equivalent of NVidia's CUDA library, making it possible to run highly parallelized computations on the GPU. Cuda is open source and supports using multiple GPUs at the same time to perform the same computation.
Currently, Tabby with ROCm is only supported on Linux, and can only be run directly from a compiled binary. In the future, Tabby will be able to run with ROCm on Windows, and we will distribute a Docker container capable of running with ROCm on any platform.
Install ROCm
Before starting, please make sure you are on a supported system and have ROCm installed. The AMD website details how to install it, find the instructions for your given platform. Shown below is a successful installation of ROCm packages on Arch Linux.

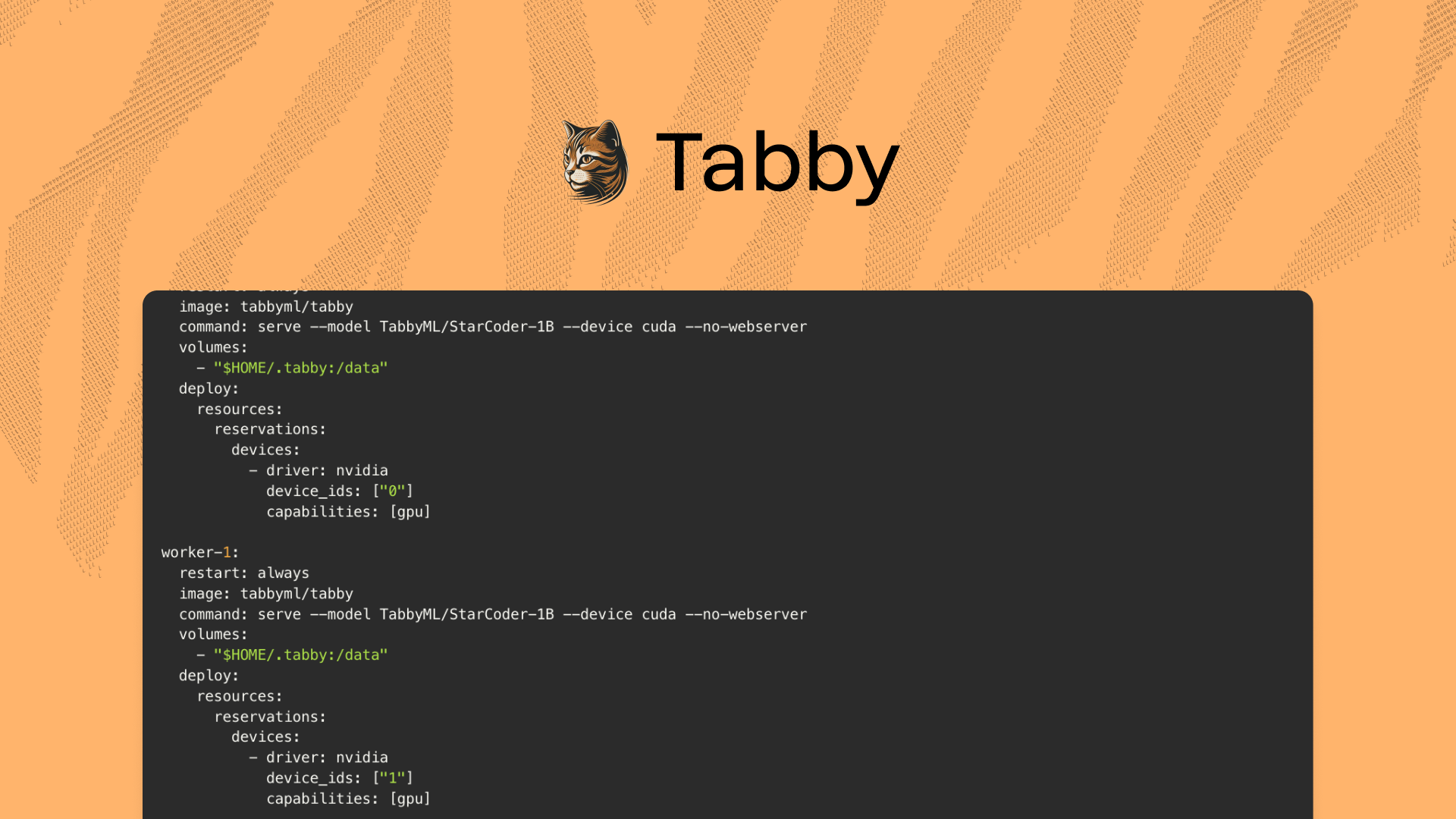
Deploy Tabby with ROCm from Docker
Once you've installed ROCm, you're ready to start using Tabby! Simply use the following command to run the container with GPU passthrough:
docker run \
--device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined --group-add video \
-p 8080:8080 -v $HOME/.tabby:/data \
tabbyml/tabby-rocm \
serve --device rocm --model StarCoder-1B
Deploy Tabby with ROCm from Docker
Once you've installed ROCm, you're ready to start using Tabby! Simply use the following command to run the container with GPU passthrough:
docker run \
--device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined --group-add video \
-p 8080:8080 -v $HOME/.tabby:/data \
tabbyml/tabby-rocm \
serve --device rocm --model StarCoder-1B
The command output should look similar to the below:

Build Tabby with ROCm locally
If you would rather run Tabby directly on your machine, you can compile Tabby yourself. If compiling yourself, make sure to use the flag --features rocm to enable it.
Once you have a compiled binary, you can run it with this command:
./tabby serve --model TabbyML/StarCoder-1B --device rocm
If the command is used correctly and the environment is configured properly, you should see command output similar to the following:

And enjoy GPU-accelerated code completions! This should be considerably faster than with CPU (I saw a ~5x speedup with StarCoder-1B using a Ryzen 7 5800X and an RX 6950XT).

Stay Updated with Tabby News
Subscribe to our newsletter for the latest updates and news about Tabby.


.png)
Discover Tabby Unlock Your Coding Potential
Get Started with our Community Plan Today
Simple self-onboarding
Free community plan
Local-first deployment
Explore Full Features with Team or Enterprise Plans
Enterprise-first experience
Flexible deployment options
Enhanced security support